The AMD 3rd Gen Ryzen Deep Dive Review 3700X and 3900X Raising The Bar AnandTech

Forbidden
You don't have permission to access /api.php
on this server.
Additionally, a 403 Forbidden | |||||||||||
| error was encountered while trying to use an ErrorDocument to handle the request. | L2 | L3 | |||||||||
| 8C | |||||||||||
| 8C | |||||||||||
| 6C | |||||||||||
| 6C |
is launching 5 different SKUs today, with the 16-core set to follow sometime in September. For today's launch sampled the R9 and R7 , and we took them for a ride in the limited time we had with them, covering as much as we could.
Starting at the top we have the Ryzen , which is a 12-core design. In fact it's the first 12-core processor in a standard desktop socket, and it rather unique within 's product stack because it is currently the only SKU which takes full advantage of ’s newest chiplet architecture. Whereas all the other Ryzen parts are comprised of two chiplets – the base I/O die and a single CPU chiplet – comes with two such CPU chiplets, granting it (some of) the extra cores and the 64MB of L3 cache that entails.
Interestingly, while has increased the core-count by 50% over its previous flagship processor, it has managed to keep the to the same as on the Ryzen 2700X. On top of this, the chip clocks in 300MHz faster than the predecessor in terms of boost clock, now reaching GHz; even the base clock has been increased by 100MHz, coming in at GHz. The big question then, is whether the new 7nm process node and Zen 2 are really this efficient, or should we be expecting more elevated power numbers?
Meanwhile our second chip of the day is the new Ryzen , which is configured and positioned as a particularly efficient model. With a boost clock of GHz and a base clock of GHz, the part should still be notably faster than the Ryzen 2700X, yet has managed to make this a part which is going to make for some interesting analysis.

Large Performance s, Particularly for Gaming

Positioning the Ryzen 3000 series against ’s line-up is a matter of both performance as well as price. had already made comparisons between the new SKUs and ’s counterparts back at Computex, where we saw comparisons between similarly priced units. According to the company, even 's pricey Skylake high-end desktop (HEDT) processor, the Core i9-9920X, isn't entirely out of the line of fire of the Ryzen .
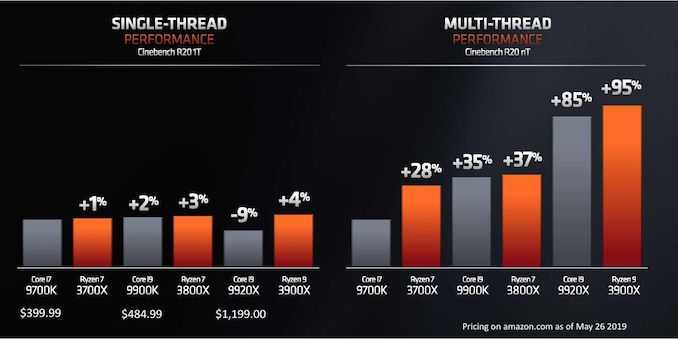
| Comparison: vs | ||